
Dunia web sedang mengalami pergeseran paradigma yang paling radikal sejak pertama kali diciptakan. Kalau dekade lalu kita fokus membangun website untuk dibaca oleh mata manusia (Human-Centric Web), bulan Juni 2026 ini kita harus mengakui bahwa pengunjung yang paling rajin menguras trafik server kita adalah barisan robot, crawler, dan agen AI seperti ChatGPT, Gemini, Claude, dan Perplexity.
Masalahnya, saat agen-agen AI ini mengunjungi website tradisional, mereka sering tersandung oleh sampah visual. Mereka kebingungan membaca skrip JavaScript yang berat, CSS yang berantakan, dan struktur HTML yang tidak efisien. Berangkat dari masalah ini, komunitas teknologi global menetapkan standar baru yang disebut Agent-Ready Web Standards.
Artikel ini merangkum secara komplit proses perombakan blog Layar Kosong oleh saya sendiri di Balikpapan. Perombakan total ini sukses meraih skor mutlak 100/100 (Level 5 Agent-Native) pada sistem audit global isitagentready.com.
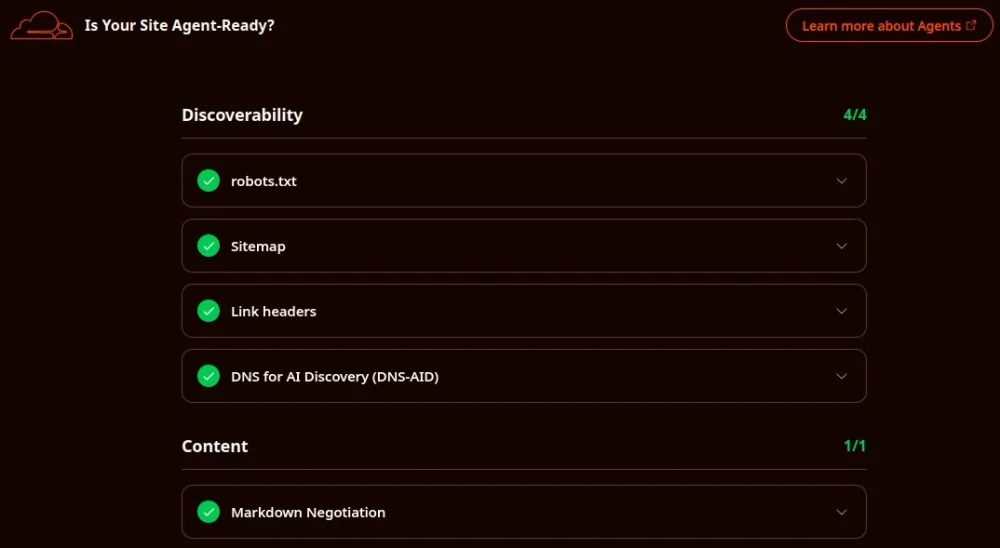
Bagian 1: Discoverability Tingkat Tinggi & DNS-AID
Sebelum agen AI memproses konten, ia harus tahu letak pintu masuk yang benar tanpa harus menjelajah tanpa arah yang jelas. Kita menggunakan ekosistem Cloudflare DNS untuk mengeksekusi dua mekanisme ini:
1. DNS for AI Discovery (DNS-AID)
Mengacu pada draf IETF (draft-mozleywilliams-dnsop-dnsaid), AI masa kini bisa melakukan pencarian langsung di tingkat DNS. Pada sistem Layar Kosong, dua record berjenis SVCB/HTTPS dipasang di bawah subdomain agensi:
_index._agents.dalam.web.id_a2a._agents.dalam.web.id
Record ini membawa parameter alpn dan penunjuk endpoint. DNS resolver langsung mengembalikan data otentik kepada bot AI bahkan sebelum koneksi HTTP terjadi.
2. Suntikan HTTP Link Headers
Lewat file _headers statis di Cloudflare Pages*, server menyuntikkan relasi *link langsung ke dalam HTTP Response Header tanpa menunggu HTML selesai dimuat:
/*
Link: ; rel="agent-skills"
Link: ; rel="api-catalog"
Link: ; rel="alternate"; type="text/markdown"
Link: ; rel="alternate"; type="text/markdown"
Bagian 2: Content Negotiation & Dualitas File LLMS
Menyumpal ribuan halaman HTML utuh ke memori AI adalah pemborosan token. Layar Kosong merakit penambang artikel dinamis berbasis Bun yang memilah konten menjadi dua wujud, tanpa perlu berurusan dengan relasi database creation yang rumit:
- llms.txt (Buku Menu): File ringan di folder
.well-knownberisi judul, ringkasan satu baris, dan URL asli sebagai peta jalan agen AI. - llms.md (Gudang Arsip): Skrip Bun membedah file HTML asli, membuang elemen pengganggu, dan mengonversi tag inti menjadi format Markdown padat gizi.
Melalui lapisan middleware via _middleware.ts, bot yang membawa header Accept: text/markdown akan otomatis dibelokkan untuk disuapi file Markdown tanpa merusak antarmuka HTML bagi pengunjung manusia.
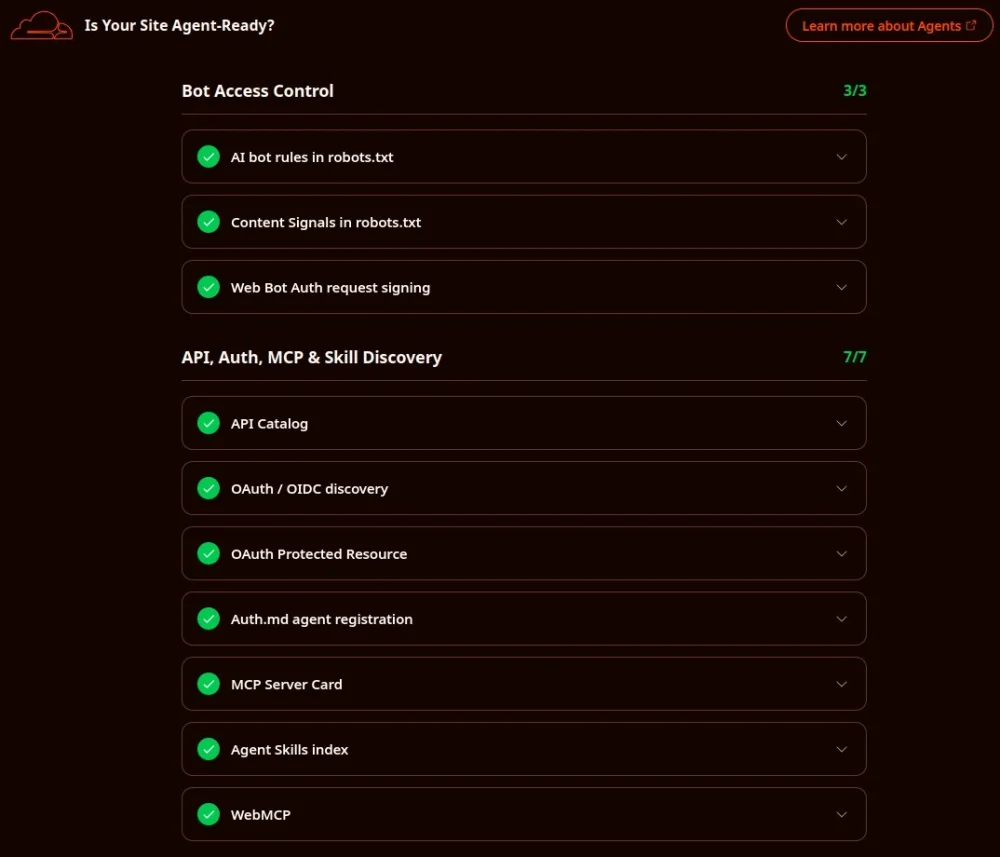
Bagian 3: Kontrol Akses Bot & Content Signals
Situs cerdas tegas mengatur batasan hukum penggunaan datanya.
1. Sinyal Konten di robots.txt
Sesuai draf contentsignals.org, kita menanamkan instruksi yang melarang keras raksasa AI melatih model dasar mereka memakai konten kita (ai-train=no), tapi tetap mengizinkan pembacaan untuk keperluan pencarian (search=yes).
2. Web Bot Auth Request Signing
Sebuah file tanpa ekstensi http-message-signatures-directory dipublikasikan. Isinya adalah JSON Web Key Sets (JWKS) kriptografi Ed25519 untuk verifikasi HTTP Message Signatures yang absolut.
Bagian 4: API Catalog & Birokrasi Autentikasi
Karena konten Layar Kosong bersifat Open Access dan public domain, kita membuat replika arsitektur statis untuk melompati birokrasi ini dengan mulus. File .well-known/api-catalog disajikan untuk mendeklarasikan peta website. Kita juga menjinakkan spesifikasi auth.md dengan menanamkan blok peringatan bahwa bot bisa melewati birokrasi ini karena tidak ada sistem login.
Akhirnya, file agent-card.json dan mcp/server-card.json diaktifkan untuk menyambut ekosistem Model Context Protocol (MCP). Meracik web modern bukan sekadar visual yang wah, tapi struktur yang patuh protokol.!